I am using two kinds of component resource allocation combinations.
Could you advise me what part I'm missing because the two allocation methods have a lot of performance difference in CPL COMM?
#A

#B

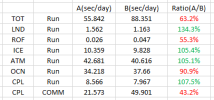
The difference between #A and #B is that B has fewer resources in OCN and more resources in ATM and ICE.
RESULT

Slightly slower on OCN and faster on ATM, ICE, and LND performed the same as given the resource.
However, it was confirmed that the CPL COMM was abnormally slow. I'm curious what caused this.
I'd like to get some guidance on how to allocate resources and try to do it.
Best Regards,
Kihang
Could you advise me what part I'm missing because the two allocation methods have a lot of performance difference in CPL COMM?
#A
#B
The difference between #A and #B is that B has fewer resources in OCN and more resources in ATM and ICE.
RESULT
Slightly slower on OCN and faster on ATM, ICE, and LND performed the same as given the resource.
However, it was confirmed that the CPL COMM was abnormally slow. I'm curious what caused this.
I'd like to get some guidance on how to allocate resources and try to do it.
Best Regards,
Kihang